Step-by-Step Guide to Setting Up Medallion Architecture on AWS

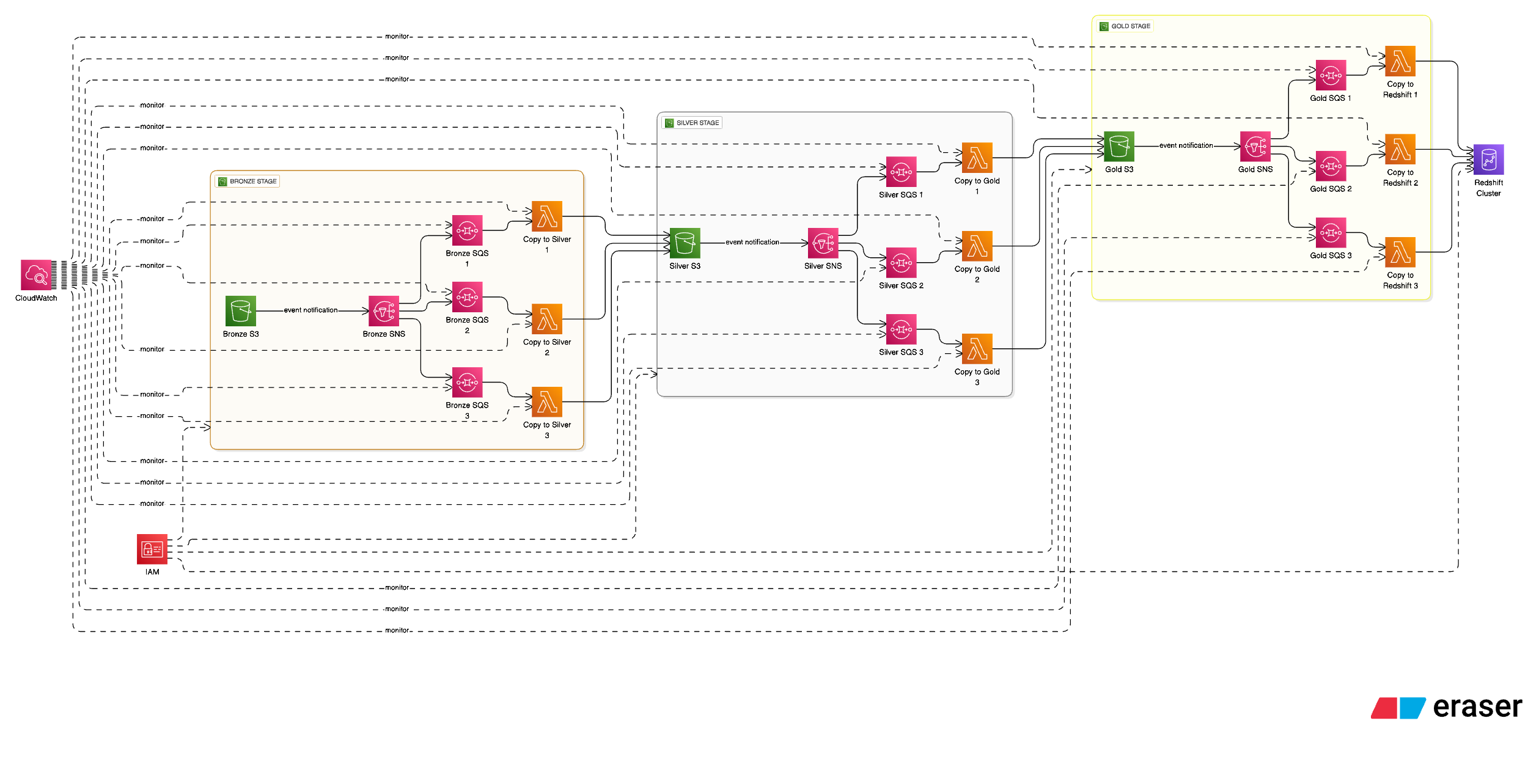
Modern analytics platforms require structured and reliable data processing pipelines. The Medallion Architecture—Bronze → Silver → Gold—provides a standardized way to achieve this while maintaining quality, lineage, and re-processing capabilities.
In this post, we walk through how we implemented a fully serverless Medallion Pipeline on AWS.
Architecture Summary
Your data flows through three refinement layers:
1. Bronze Layer — Raw, Immutable Data
The Bronze layer is intentionally raw, meaning:
➤ What goes into Bronze?
Exact copy of source data
Same schema, same naming, same format
No transformation, enrichment, or filtering
➤ Purpose of Bronze
✔ Preserve original fidelity
✔ Enable audit & lineage
✔ Allow re-processing if logic changes
Typical files include:
JSON dump from source applications
CSV batch exports from 3rd-party systems
IoT logs, streaming output
Parquet snapshots
When files land in Bronze S3, an event notification triggers:
Bronze SNS → Bronze SQS
SQS message invokes Bronze Lambdas
Bronze Lambda does NOT modify original data.
Instead it: ✔ Registers metadata,
✔ Validates file existence,
✔ Moves/copies file into Silver format zone,
But original file remains archived in Bronze untouched.
2. Silver Layer — Validated and Structured
Silver is where real transformation begins.
What Silver accomplishes:
✔ Converts files into standardized formats (often Parquet)
✔ Applies schema validations
✔ Removes incorrect or malformed rows
✔ Deduplicates
✔ Standardizes timestamps, naming conventions
Outputs of Silver
Clean structured tables
Partition-based data
Domain-level refined datasets
Once processed, Silver pushes events to:
Silver SNS
Multiple Silver SQS Consumers
Each Lambda:
merges incrementally
enriches reference data (e.g., dimension lookups)
prepares transformation logic for Gold
Gold Layer — Analytics-Ready Curated Data
Gold is the final consumer-facing layer.
Gold contains:
✔ curated dimensional models
✔ aggregated KPIs
✔ business metrics
✔ reporting-ready tables
Examples:
fact_sales fact_orders dim_customer dim_product
Gold Lambdas copy into: ➡ Redshift
➡ Data Lake Analytical Zone
Gold is optimized for:
BI tools like Tableau, Power BI, Looker
Machine learning training datasets
Regulatory reporting
Event-Driven Flow (End-to-End)
Raw files are ingested into Bronze S3, which publishes an event to SNS. SNS fans out messages to SQS, providing durability and retry handling. Lambda consumes messages from SQS, processes the data, and writes to Silver S3. The same SNS → SQS → Lambda pattern continues from Silver S3 to Gold S3, and finally loads data into the Warehouse.
This loosely coupled architecture enables independent scaling, fault isolation, and reliable event-driven processing at each layer.
Raw File
↓
Bronze S3
↓ (S3 Event)
SNS Topic
↓ (Fan-out)
SQS Queue
↓ (Durable, Retryable)
Lambda Function
↓
Silver S3
↓
SNS → SQS → Lambda
↓
Gold S3
↓
Warehouse Load
armasmLifecycle Policies
We apply these automatically:
Layer | Retention | Why |
Bronze | long-term archive (90-365 days) | audits & re-processing |
Silver | medium (30-90 days) | repeat processing rare |
Gold | retention aligned to business SLAs | analytics usage |
Key Benefits Achieved
Business Value
✔ trustable analytics
✔ audit trail always preserved
✔ domain-based ownership
Developer Productivity
✔ pipeline stages decoupled
✔ minimal operational burden
✔ easy module reusability
Cost Efficiency
✔ serverless scaling
✔ retention optimizations
✔ optimized warehouse loads
Final Thoughts
This architecture aligns 100% with modern Medallion standards:
Bronze = source-truth immutable history
Silver = high-quality structured data
Gold = curated business-level data
Using Terraform allowed deployment of:
buckets
queues
triggers
security controls
compute functions
with minimal manual configuration.
Wrap Up
To learn on how to create the actual architecture using terraform you can contact me from the Connect Page